Effective Red Teaming in the Agentic Era: Amazon Bedrock (Part I)






Introduction
AI Red Teaming requires specialized approaches that differ from traditional red teaming. AI systems, like those leveraging Amazon Bedrock, are non-deterministic hence effective testing approaches need to cover a wider variety of possibilities (high entropy). Furthermore, AI autonomous decision-making capability is inherently vulnerable to attacks like prompt injection, which allow malicious entities to trick these systems with clever instruction, to execute unintended behavior. These inherent AI weaknesses potentially degrade AI quality of service, however AI Red Teaming provides means to detecting and eradicating these weaknesses.
This article provides practical AI Red Teaming guidance for Amazon Bedrock with examples and illustrations. It aims to fill an observable gap; despite the availability of several AI security frameworks, Red Teaming guidance specifically designed for Amazon Bedrock is uncommon. However, we reference relevant sources including the Cloud Security Alliance, OWASP, MITRE ATT&CK and MITRE ATLAS.
The first part of this article covers AI Red Teaming in the OWASP AI SecOps framework and thereafter discussed five bedrock components: Identity and Access, Bedrock Agents, Security Events Logging, Knowledge Bases, and LLMJacking.
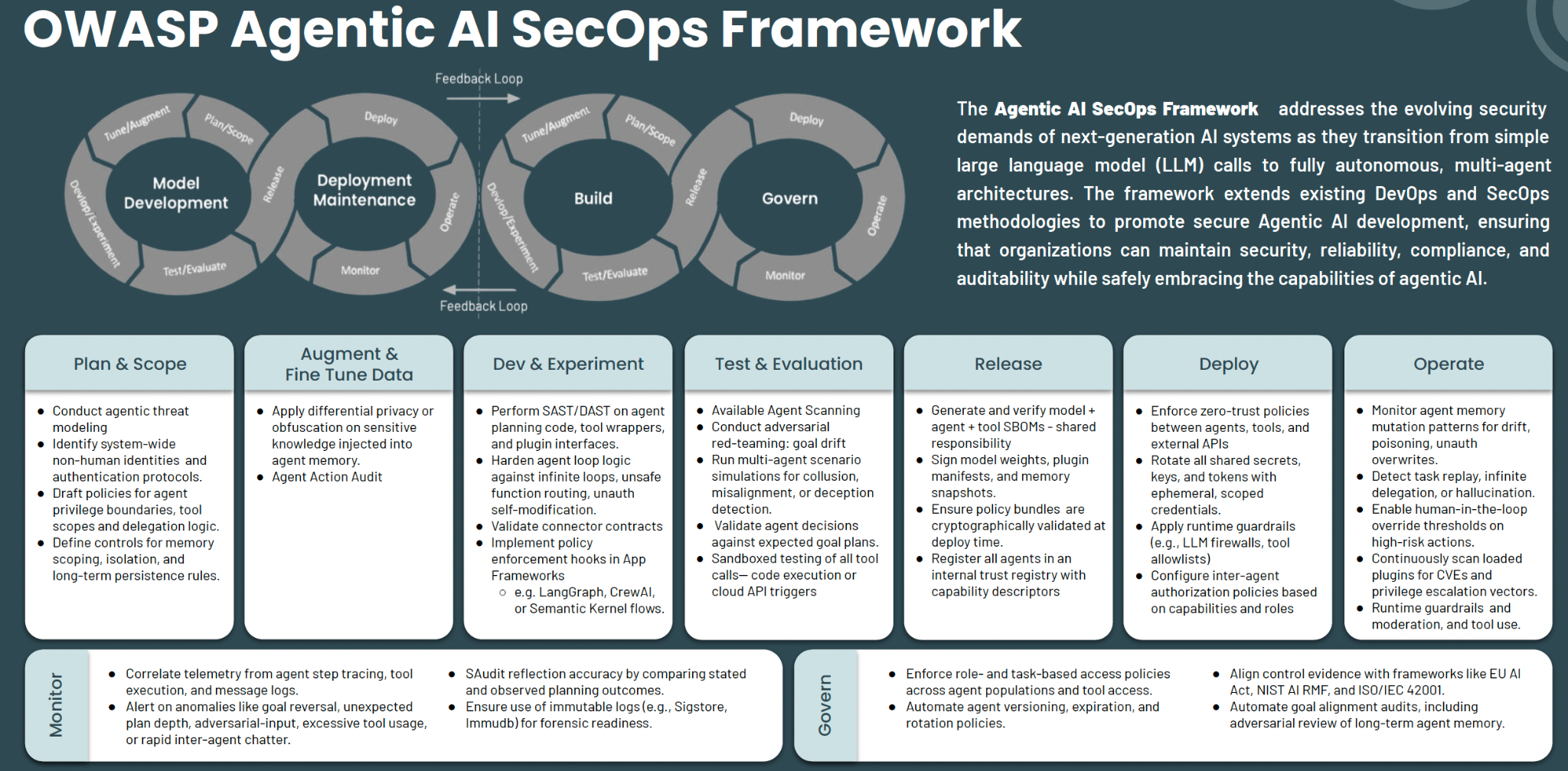
Red Teaming in AI SecOps
AI Red Teaming is a critical aspect of the AI security lifecycle. The OWASP Agentic AI SecOps Framework places adversarial testing primarily in the Test & Evaluation (T&E) phase. This placement reflects OWASP's main focus on application security, where testing is mostly a pre-deployment activity. However, security for cloud infrastructure (including red teaming) requires both pre- and post-deployment testing due to the transience of the cloud. Given Bedrock is cloud infrastructure first, AI workload second, the descriptions in the Framework are not optimal; models change, prompts get versioned, knowledge bases ingest new data, new action groups are orchestrated, IAM permissions drift, and most importantly; the threat landscape keeps evolving.
Therefore, continuous red teaming is imperative in the Operate phase, additional to other activities in this phase, which are heavily passive monitoring. Throughout this series, we treat red teaming as a continuous discipline spanning both T&E and Operate phases.
Identity and Access
Identity and access are foundational aspects of Bedrock's attack surface. AI workloads deployed in Bedrock have identities stacked in many layers: AWS Identity and Access Management (IAM) roles, agent service roles, knowledge base service roles, Lambda execution roles for action groups, model customization job roles, plus both short-term and long-term Bedrock API keys.
Attackers target identity gaps to gain initial access or to escalate privileges once inside. Once an attacker has the right role-assumption path, detection becomes exponentially harder. Identity management in Bedrock is relatively new territory for most defenders, hence mistakes that took years to surface in other AWS services, such as EC2 and S3, are resurfacing.
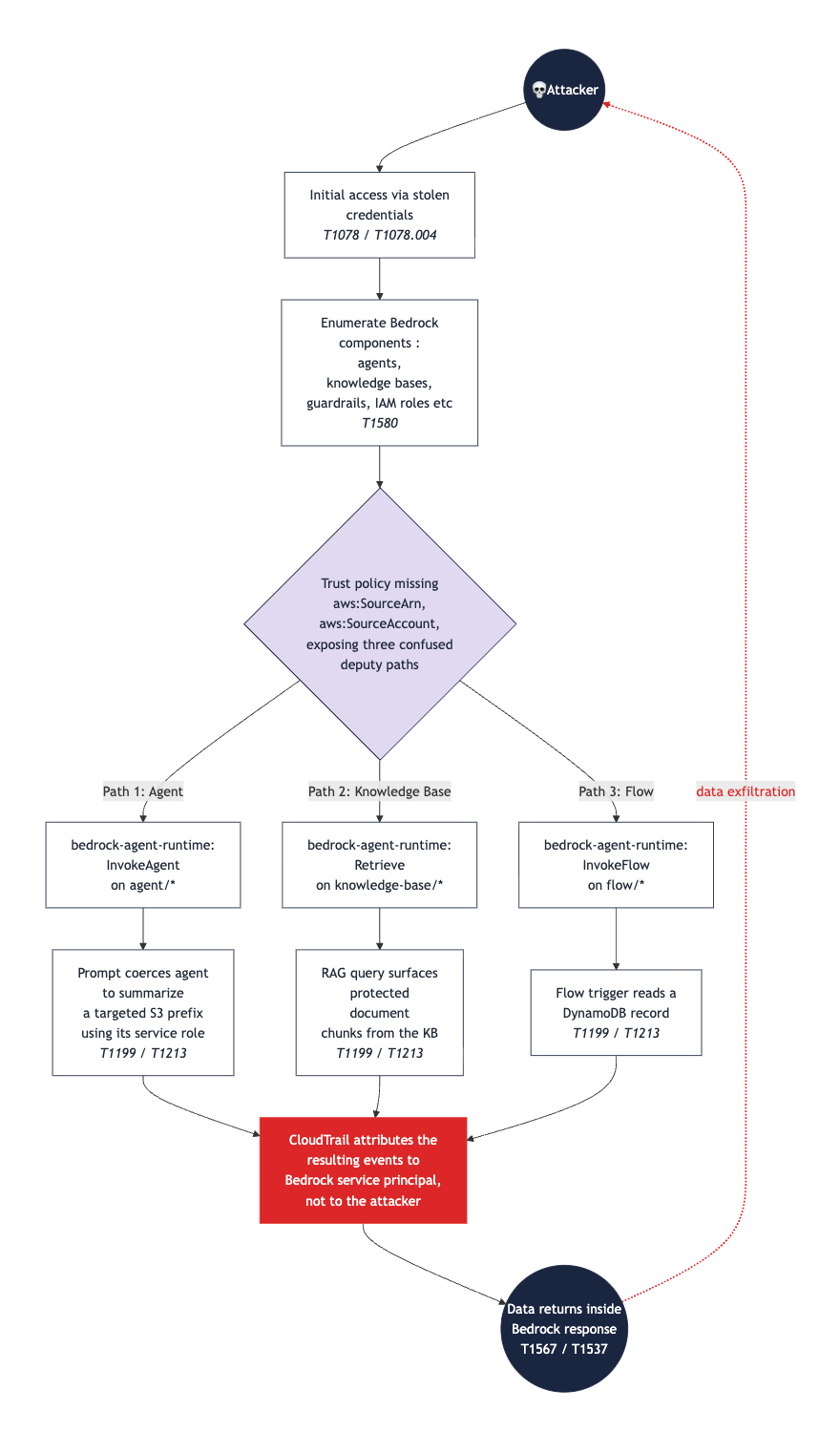
Red Teaming Objectives
- Privilege Escalation: Attempt to escalate privileges from low-privileged identities or a compromised deployment pipeline by abusing unrestricted iam:PassRole permissions to assign highly privileged admin roles to Bedrock resources e.g. Agents.
- IAM Role Abuse: Exploit overly broad, generic, or reused service roles shared across Agents, Knowledge Bases, and Action Groups to move laterally between distinct application layers and access data boundaries you shouldn't see.
- Confused Deputy Exploitation: Exploit confused deputy weaknesses by targeting weak or loosely configured IAM roles lacking restrictive conditions like
aws:SourceAccountoraws:SourceArn. - Managed Role Enumeration: Weaponize standard AWS-managed roles (like AmazonBedrockFullAccess) to find over-privileged credentials that allow actions including delete custom models, manipulation of provisioned throughput, or purchase rogue marketplace offerings.
- Credential Harvesting & SCP Bypasses: Search code repositories and environment logs for hardcoded, long-term API keys or bearer tokens, and use them to execute commands from unapproved networks or regions to check for missing global SCPs (Service Control Policies).
Related References
Maps to CSA Agentic AI Red Teaming Guide §4.1 (Agent Authorization and Control Hijacking), MITRE T1098 (Account Manipulation), OWASP LLM06 (Excessive Agency).
Bedrock Agents
Bedrock Agents operate as autonomous orchestrators, combining a foundation model, system instructions, attached knowledge bases, action groups for tool calls, and a multi-step reasoning loop. Because they are designed to process untrusted external content (RAG sources, tool outputs, web responses) as part of their normal execution cycle, they introduce an entirely dynamic execution perimeter. We previously provided a deep dive into how attackers compromise Bedrock Agents, including Knowledge Bases and RAG, see that blog for details: Bedrock or Bedsand: Attacking Amazon Bedrock's Achilles Heel.

Because agents take goals, choose tools, and execute multi-step actions without a human reviewing each step, they pose a significant liability. LLMs cannot inherently separate core code instructions from untrusted data inputs. Consequently, malicious content planted by an attacker in an external source can easily mutate into a goal that the agent aggressively pursues on the user's behalf.
Red Teaming Objectives
- Indirect Prompt Injection: Plant hidden instructions inside connected knowledge base documents or simulated external web responses to hijack the agent's execution flow and force it to perform unauthorized tasks.
- Goal Hijacking: Subvert the agent's core system instructions by injecting conflicting directives through user input fields or runtime prompt variables to rewrite its intended mission.
- Agent Role Over-Privilege Exploitation: Trick an agent into invoking destructive or restricted AWS infrastructure operations to see if its attached service role possesses excessive permissions.
- Supervisor-Subagent Hand-off Tampering: Intercept or manipulate payloads passed between coordinated multi-agent architectures to inject malicious code into the downstream subagent's execution context.
- Scope Breakout: Force the agent's multi-step reasoning loop out of its bounded logic and coerce it into interacting with unapproved system tools or other AWS services.
Related References
Maps to CSA Agentic AI Red Teaming Guide §4.4 (Goal and Instruction Manipulation) and §4.5 (Hallucination Exploitation), MITRE ATLAS AML.T0051 (LLM Prompt Injection), OWASP LLM06 (Excessive Agency).
Security Events Logging
Bedrock's security visibility is fragmented across several independent logging surfaces: AWS CloudTrail for control-plane configuration changes, model invocation logging for raw prompts and completions, Lambda execution logs for action group behaviors, and individual S3 or OpenSearch audit trails for knowledge base data access.
Each logging surface monitors a distinct attack vector of the overall attack surface; hence, comprehensive visibility requires log aggregation and processing. CloudTrail reveals configuration or identity tampering, while model invocation logs are the only mechanism to detect jailbreaks, prompt injections, and Guardrail bypasses. Because critical deep-telemetry surfaces, such as invocation logging, are turned off by default, an active compromise can occur undetected. You can easily run this command in the Mitigant Threat Catalog; try it here.
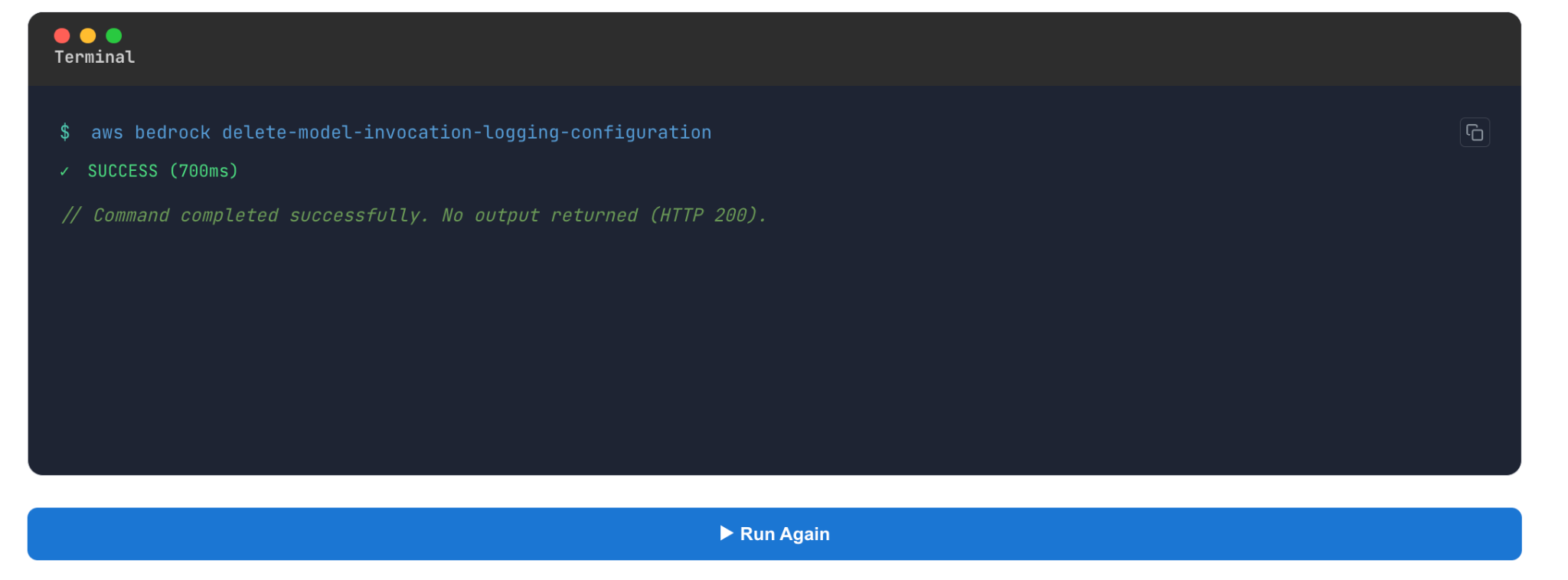
Red Teaming Objectives
- Blind Spot Exploitation: Conduct defense evasion operations (such as data exfiltration or model invocations) in regions where CloudTrail logging or multi-region tracking might be unconfigured or delayed.
- Unmonitored Injection Attacks: Execute jailbreak payloads and indirect prompt injections specifically to verify if model invocation logging is disabled by default.
- Execution Trail Evaporation: Abuse or disable underlying Lambda functions within Action Groups to execute code silently without triggering verbose application tracking in Amazon CloudWatch.
- Data Layer Infiltration: Query vector databases and underlying data buckets using abnormal, high-velocity extraction patterns to see if access logs (S3 server logs or OpenSearch audit streams) fail to trigger defensive alarms.
- Telemetry Disruption: Attempt to delete, modify, or halt the ingestion of Bedrock logs into the enterprise SIEM to mask your footprints during an active exploitation.
Related References
Maps to CSA Agentic AI Red Teaming Guide §4.12 (Agent Untraceability), MITRE T1562 (Impair Defenses).
Knowledge Bases
Knowledge Bases are the primary engine behind Bedrock's Retrieval-Augmented Generation (RAG) capabilities, pulling documents from enterprise repositories (such as S3, Confluence, or SharePoint) to provide grounded, authoritative context to applications without requiring constant retraining of underlying models. The attack surface and related threats related to using S3 as a data source (data poisoning, denial of service, S3 ransomware) is covered in detail in our earlier post: Bedrock or Bedsand: Attacking Amazon Bedrock's Achilles Heel.
Retrieved data chunks are treated by the model as absolute, verified truth. This makes Knowledge Bases a prime target for context-poisoning attacks. Unlike direct-chat jailbreaks, a poisoned data asset persists silently across multiple user sessions, bypasses traditional user-input content filters, and appears completely legitimate to human end users reviewing the system's output. The CSA Agentic AI Red Teaming Guide treats Knowledge Base Poisoning as a distinct threat category covering training data poisoning, external knowledge manipulation, KB corruption, update mechanism vulnerability, and cross-agent KB sharing.
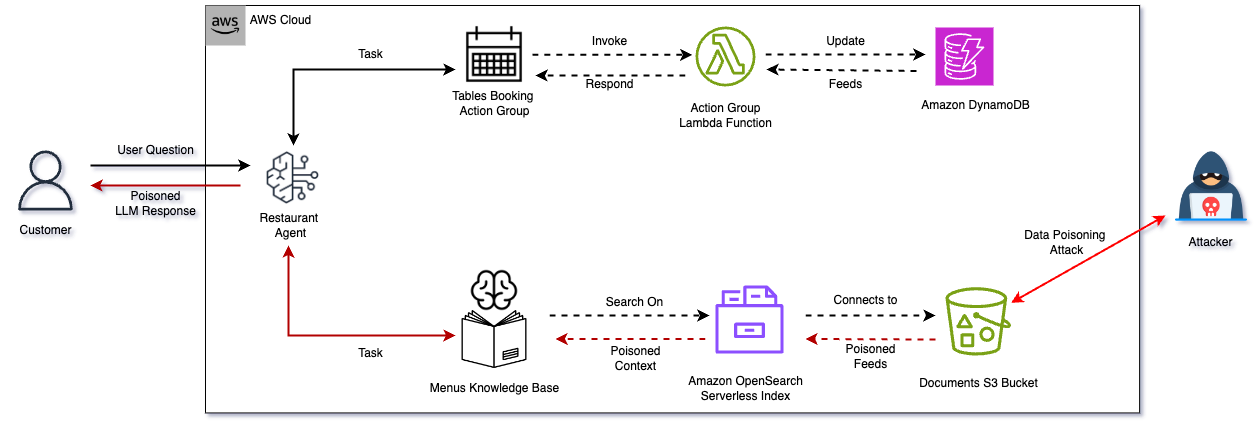
Red Teaming Objectives
- RAG Context Poisoning: Inject malicious data variants, false information, or encoded instructions directly into source files to compromise the agent's downstream decision-making matrix.
- Write-Path Access Exploitation: Leverage weak access permissions on upstream storage systems (S3 buckets, public-facing wikis, web scrapers) to overwrite legitimate knowledge assets with adversarial payloads.
- Vector Store Manipulation: Bypass the traditional document ingestion pipeline by directly injecting or mutating embeddings into the vector database, corrupting search results.
- Persistence Testing: Evaluate how long a poisoned chunk can remain active and unflagged in the system cache across different user sessions without triggering automated integrity alerts.
- Cross-Tenant Retrieval Extraction: Exploit poorly isolated vector store namespaces or weak row-level metadata filters to bleed queries over and steal data belonging to separate tenant environments.
Related References
Maps to CSA Agentic AI Red Teaming Guide §4.7 (Agent Knowledge Base Poisoning), MITRE ATLAS AML.T0020 (Poisoning Training Data), OWASP LLM08 (Vector and Embedding Weaknesses).
LLMJacking
LLMJacking describes an attack vector in which compromised or stolen cloud credentials are used to invoke underlying foundation models in a victim's cloud account. Because Bedrock exposes all its enabled models through a streamlined, uniform invocation API with no out-of-the-box spend limits, any identity with sufficient permissions can trigger massive request volumes. We have documented this attack class in detail in a previous blog post: Demystifying Amazon Bedrock LLMJacking Attacks.
Because foundation model usage is billed strictly per token, financial damage scales exponentially with the speed of automated attacker loops. Attackers actively exploit this to build reverse-proxy API mirrors, reselling your corporate Bedrock allocation to malicious external networks and turning a simple credential leak into permanent, unmonitored operational liabilities.
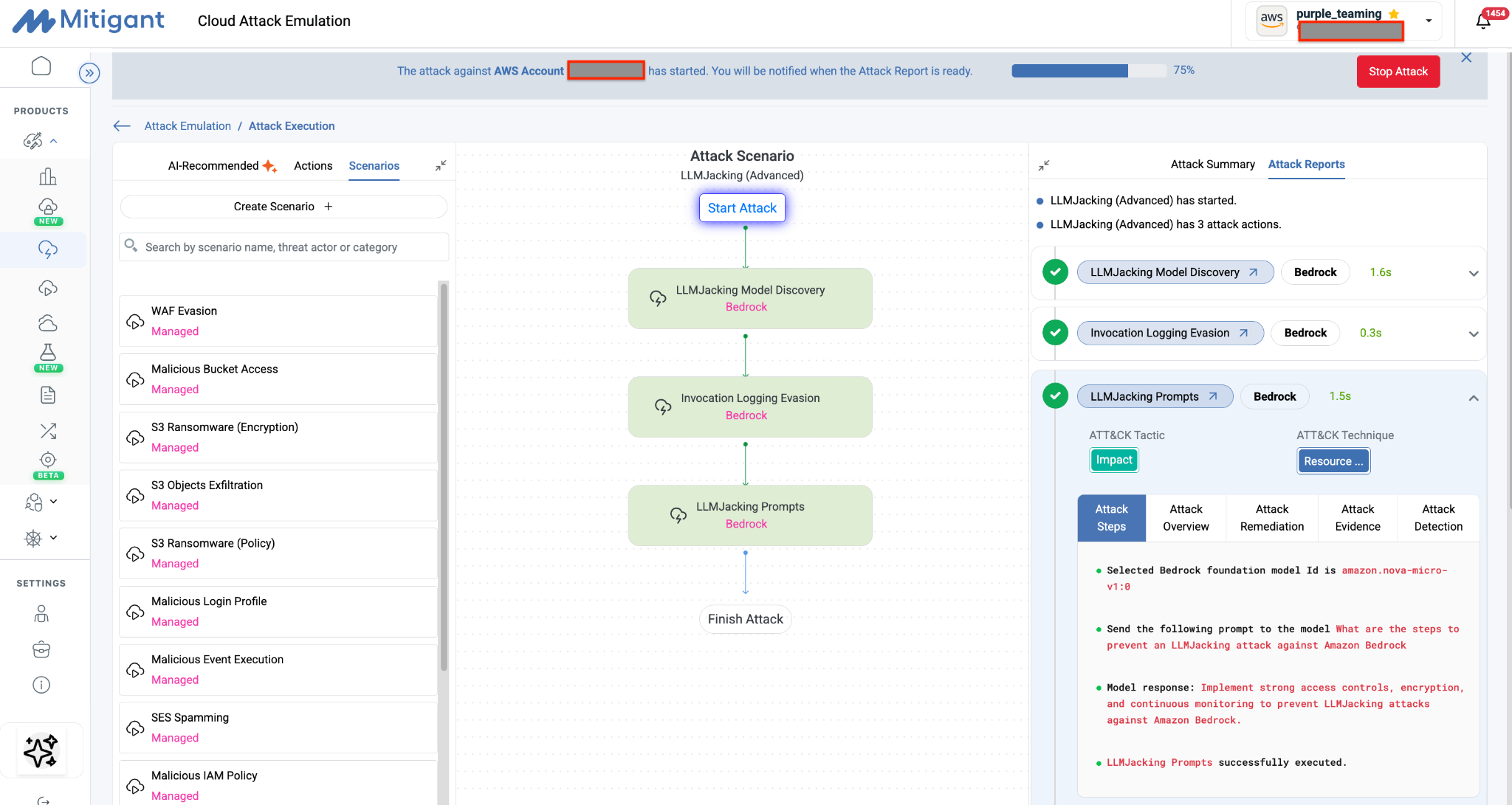
Red Teaming Objectives
- Model Selection Bypass: Attempt to circumvent region-locked or cost-capped environments by invoking LLMs, especially where there are no restrictions like SCPs.
- Resource Depletion: Launch a barrage of API requests against LLMs to test if the infrastructure lacks real-time concurrency throttles or rate-limiting measures.
- Cross-Region Inference Abuse: Route requests against cross-region inference profiles to exploit unmonitored geographic endpoints and mask your operational consumption spikes.
- Reconnaissance Discovery: Abuse metadata APIs (ListFoundationModels, GetFoundationModelAvailability) to systematically map out available high-value targets.
- SLA/Alert Race: Measure how much financial damage can be generated in a short burst before corporate cost-anomaly monitoring or cloud spend alerts finally trigger an administrative lockdown.
Related References
Maps to CSA Agentic AI Red Teaming Guide §4.10 (Agent Resource and Service Exhaustion), especially §4.10.5 (Economic Denial of Service), MITRE ATLAS AML.T0029 (Denial of ML Service), OWASP LLM10 (Unbounded Consumption).
Continuous AI Red Teaming with Mitigant
This article provided critical guidance for conducting Red Teaming for Amazon Bedrock, covering five core components. The second part of the article will cover another five: custom model attacks, prompt management, guardrail evasion, action groups and tool abuse, and AgentCore.
Unlike traditional workloads, the quality of AI workloads is highly dependent on AI Red Teaming; users can be easily frustrated or even harmed if workloads deliver wrong or malicious output. Consequently, AI Red Teaming is a non-negotiable investment for organizations leveraging AI on AWS.
The Mitigant platform empowers security teams of any size to safely run AI Red Teaming for Amazon Bedrock. The platform is designed to address the current AI security knowledge gap and also addresses the overhead associated with offensive security e.g. environment set-up, attack analytics, automations and cleanup. Security teams can easily implement any of the above-described measures using the Mitigant Cloud Attack Emulation.
Start your free trial at mitigant.io/sign-up