
AgentCore or AgentSore: Cross-Agent Privilege Escalation in Bedrock AgentCore





The Amazon Bedrock AgentCore starter toolkit ships an overly permissive IAM role that could be exploited by attackers to compromise several critical AgentCore components. This article demonstrates practical exploitation of the kill chain that exploits this weakness, with details across attack telemetry, attack detection, and countermeasures.
Introduction
Recently, Palo Alto Networks Unit 42 disclosed a privilege-escalation weakness in Amazon Bedrock AgentCore that enables cross-agent attacks, including unauthorized access to agent container images and memory. The cross-agent attacks are also exploit weak trust boundaries that should ensure only authorized operations. This article examines how we operationalized these weaknesses as an attack scenario in Mitigant Cloud Attack Emulation (CAE), allowing organizations to safely validate the impact of the exposure and assess the effectiveness of their defenses.
The scenario emulates a complete cross-agent privilege-escalation chain spanning four attack paths exposed by the over-privileged IAM execution role. While the original Unit 42 disclosure demonstrated image and memory abuse paths, the Mitigant attack scenario validates all four attack paths, operationalizes them as a repeatable attack chain, analyzes the resulting telemetry and detection opportunities, and provides countermeasures.
As adoption of AI services continues to accelerate, understanding and validating these trust-boundary failures and related weaknesses is increasingly important for securing agentic workloads, especially those running on Amazon Web Services.
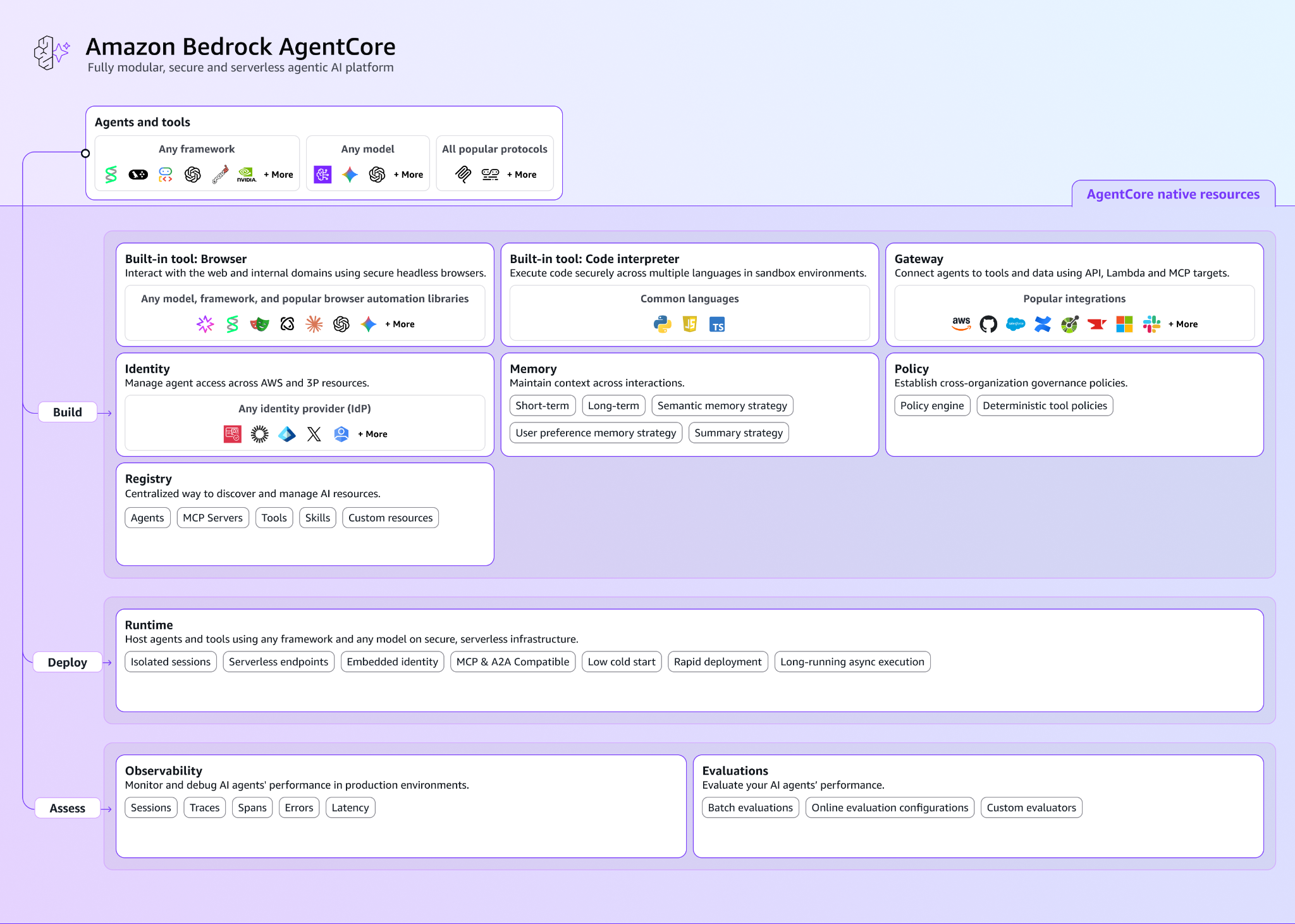
AgentCore: A Quick Architecture Primer
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating AI agents, agnostic to the underlying frameworks and Large Language Models (LLMs). When an organization deploys an agent through the starter toolkit, AgentCore provisions a set of components including:
- Runtime: the serverless execution environment that hosts agents, with each session in an isolated microVM.
- Memory: the managed store for short-term and long-term agent state, including conversation history, user preferences, and semantic facts.
- Code Interpreter: a sandboxed environment where an agent writes and executes code dynamically, under its own IAM role.
- Identity: the credential management service for inbound and outbound authentication.
- Elastic Container Registry (ECR): where AgentCore Runtime images are pushed and pulled.
- IAM Execution Role: the identity an agent assumes to act on the other components.

When Simplicity Goes Wrong: Overly Permissive IAM Role
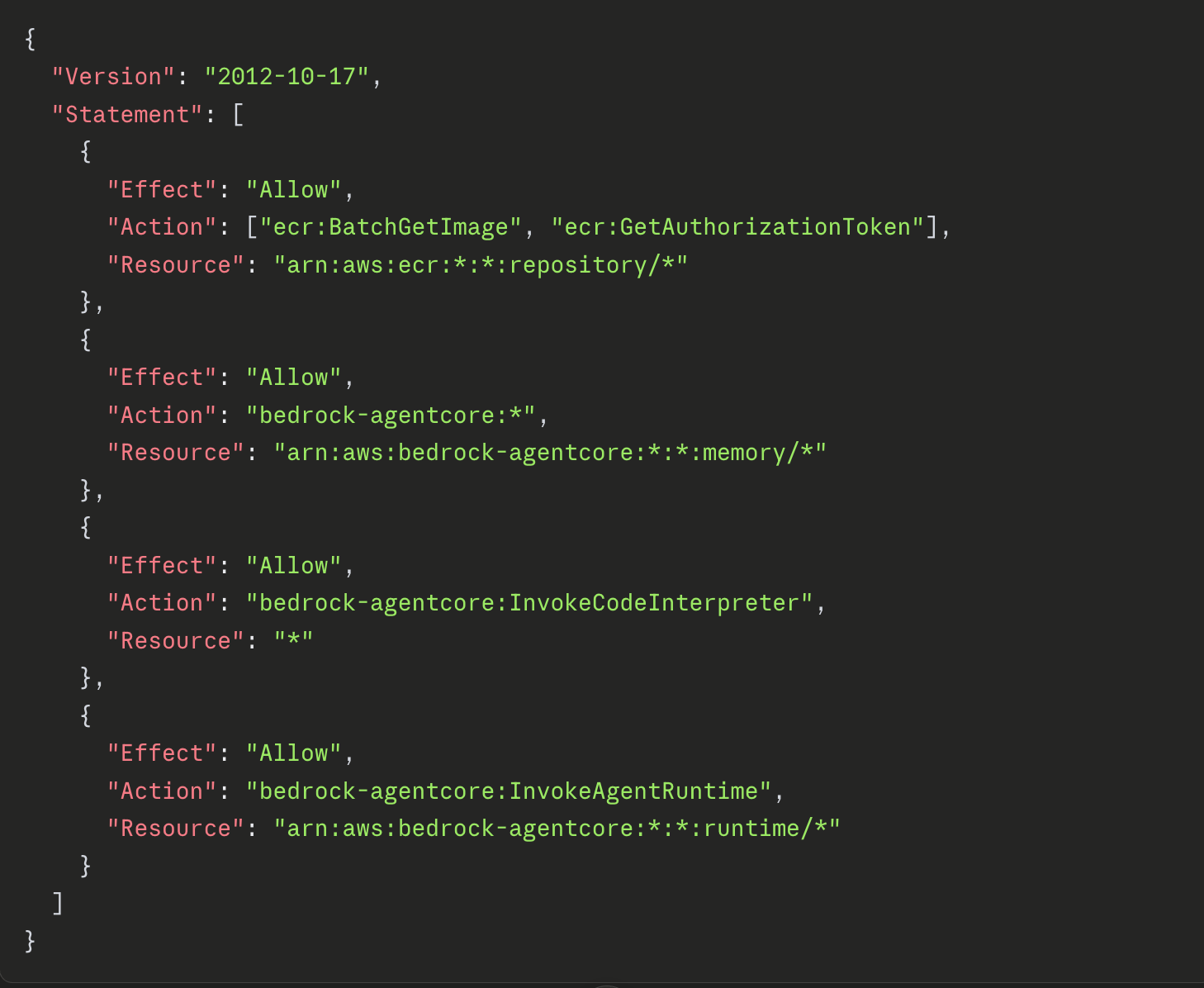
The AgentCore starter toolkit auto-generates an IAM role (Figure 3) with wildcard scopes, thus violating least privilege and opening four attack paths into the AgentCore infrastructure. The IAM role is the central trust anchor: every action an agent takes against Memory, Code Interpreter, Runtime, and ECR is authorized by it, so its properties determine the blast radius of a compromise.
The wildcard role grants account-wide permissions across four AgentCore surfaces. The dangerous part is the resource scope: each statement targets a wildcard (*) rather than the agent's own resources.
- ecr:BatchGetImage on repository/*: pull any container image in the account.
- bedrock-agentcore:* on memory/*: read or write any agent's memory store.
- bedrock-agentcore:InvokeCodeInterpreter on *: invoke any code interpreter.
- bedrock-agentcore:InvokeAgentRuntime on runtime/*: invoke any agent runtime.
Together these permissions compose a complete cross-agent compromise primitive: any agent can pull any other agent's image, read or poison any other agent's memory, execute code under any other agent's interpreter role, and invoke any other agent's runtime directly. Note that AWS no longer supports the Starter Toolkit; the recommended path is now the AgentCore CLI. This does not retroactively fix deployments already created with the toolkit, so any agent provisioned with it may still carry the over-permissioned execution role until the role is manually rescoped.
Anatomy of the Kill Chain: Four Attack Paths, One Trust Anchor
The cross-agent privilege escalation weakness has been implemented as a Mitigant attack scenario that can be easily and safely orchestrated in a repeatable manner. The scenario provisions two AgentCore agents in the same account: a Malicious Agent (Agent A) and a Victim Agent (Agent B). The wildcard execution role from the starter toolkit is attached to Agent A, which in turn attacks Agent B and executes the four attack paths illustrated in Figure 4.
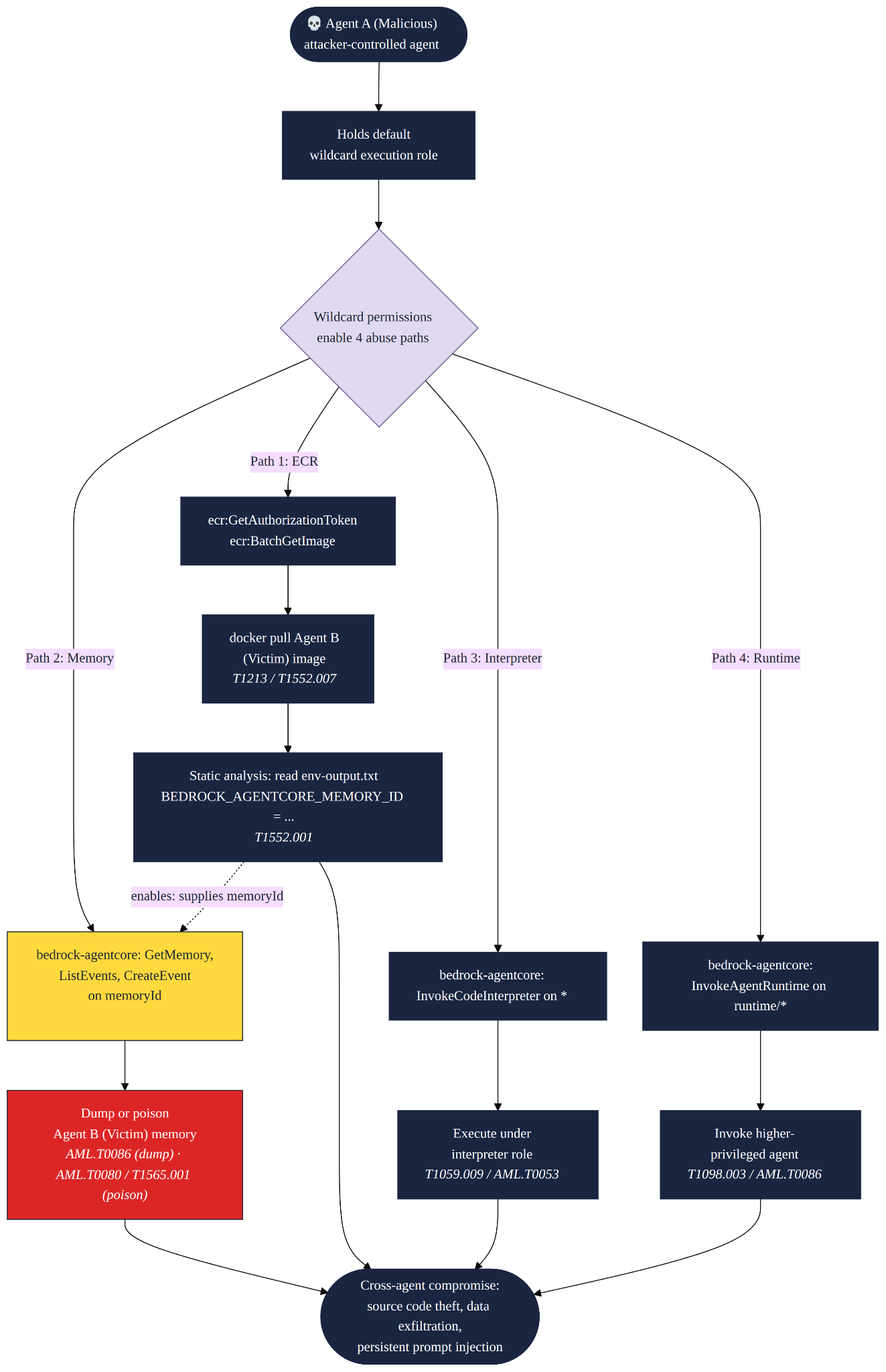
Attack Path 1: Cross-Agent ECR Image Exfiltration
Using the wildcard ECR permissions, Agent A pulls Agent B's container image from the registry. Container images often contain sensitive material: source code, proprietary algorithms, configuration, embedded secrets, etc; unauthorized access and subsequent exfiltration is a considerable risk. It also sets up the conditions for successfully executing Path 2: extraction of Agent B's Memory ID (BEDROCK_AGENTCORE_MEMORY_ID) from the container's env-output.txt file. The Memory ID is the only barrier to cross-agent memory access. Both the repository read (T1213, Data from Information Repositories) and the credential recovery (T1552.001, Credentials In Files) seems like legitimate API activity, thereby complicating detection.
Attack Path 2: Cross-Agent Memory Access and Poisoning
With Agent B's Memory ID from Path 1, Agent A abuses the wildcard memory permissions against Agent B's memory store. Agent A dumps the memory with bedrock-agentcore:ListEvents, returning conversation history, user preferences, and accumulated semantic facts (MITRE ATLAS AML.T0086, Exfiltration via AI Agent Tool Invocation).
In the attack scenario, a single ListEvents request exposed the victim agent's conversation history, including production API credentials, tenant revenue metrics, customer-support interactions, and identity-verification data. The retrieved records demonstrated how cross-agent memory access can expose both sensitive business information and operational secrets from otherwise isolated agent workloads (see Figure 5).
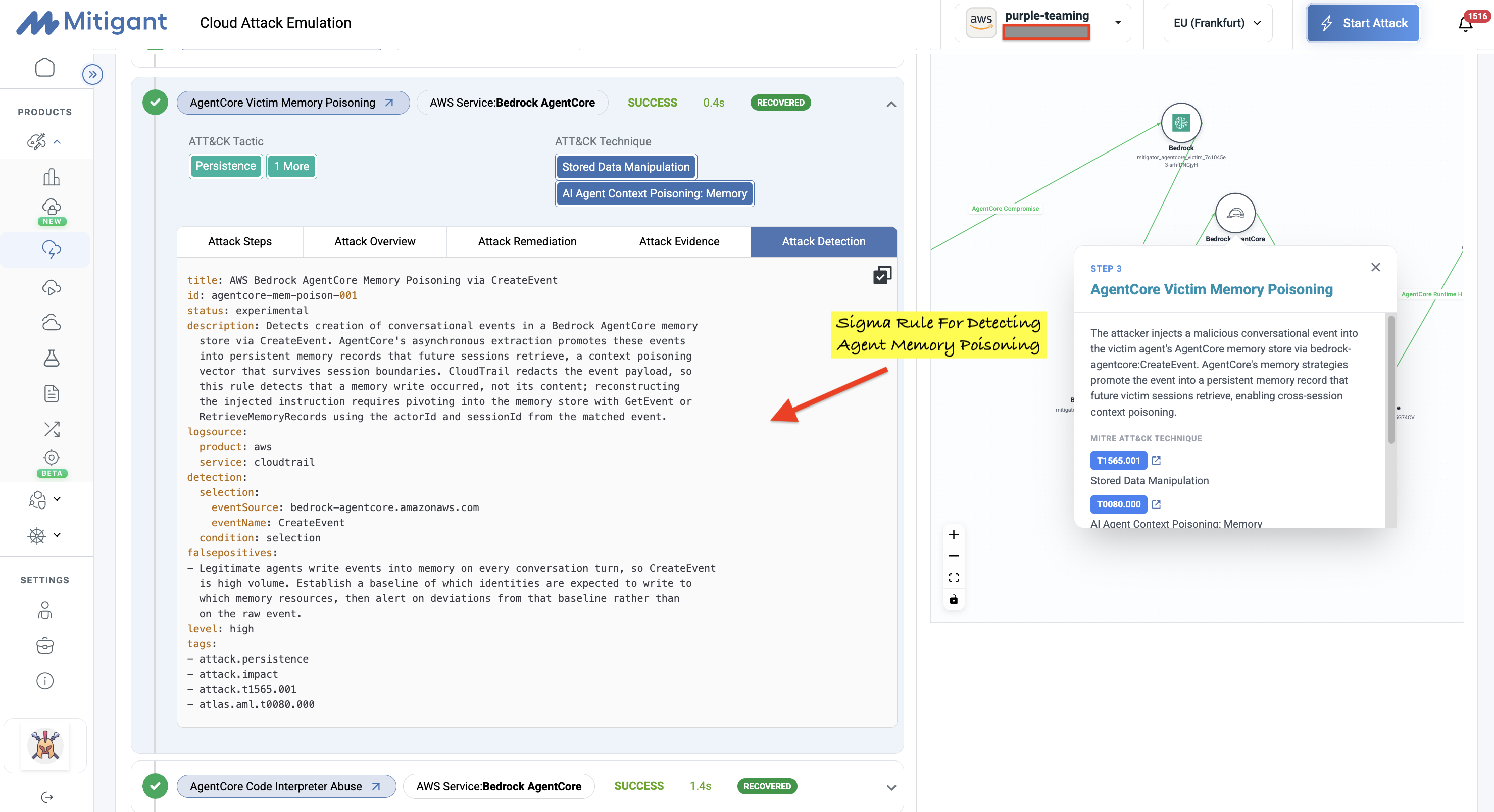
Agent A then poisons the store with a CreateEvent call that injects malicious content, which propagates into Agent B's future reasoning through AgentCore's memory consolidation strategies (ATLAS AML.T0080, AI Agent Context Poisoning: Memory). The injected instruction turns every future reply into a silent exfiltration channel, and because AgentCore promotes the event into a structured memory record, it persists across sessions. Poisoning is especially dangerous in agentic systems because it persists across sessions and quietly alters behavior over time, without the obvious indicators that disk- or network-based persistence would generate.
Attack Path 3: Code Interpreter Privilege Escalation
Code interpreters in AgentCore execute under their own IAM roles, distinct from the invoking agent's, so any code runs with the interpreter's permissions, not Agent A's. The wildcard InvokeCodeInterpreter permission on * lets Agent A reach every interpreter in the account, not just its own. This opens an indirect escalation path: Agent A enumerates the available interpreters, identifies one whose role holds permissions its own does not, and pivots by executing code in that context. The escalation is not automatic; it depends on finding a more capable interpreter role, but the wildcard scope is what makes the search possible. This maps to MITRE ATT&CK T1059.009, Command and Scripting Interpreter: Cloud API and ATLAS AML.T0053, AI Agent Tool Invocation.
Attack Path 4: Cross-Agent Runtime Hijack
Leveraging the wildcard InvokeAgentRuntime permission, Agent A can invoke any AgentCore agent runtime and pass arbitrary prompts. The consequence is that compromised agent runtimes would execute given instructions under their identity, against their own tools, memory, and permissions. This crosses the trust boundaries organizations assume between agents of different sensitivity: a finance agent receiving malicious instructions from a developer-tools agent, an admin agent manipulated by a customer-support agent. The response returns to Agent A, usable for direct exfiltration or as a step in a longer multi-agent chain. This maps to ATLAS AML.T0086, Exfiltration via AI Agent Tool Invocation.
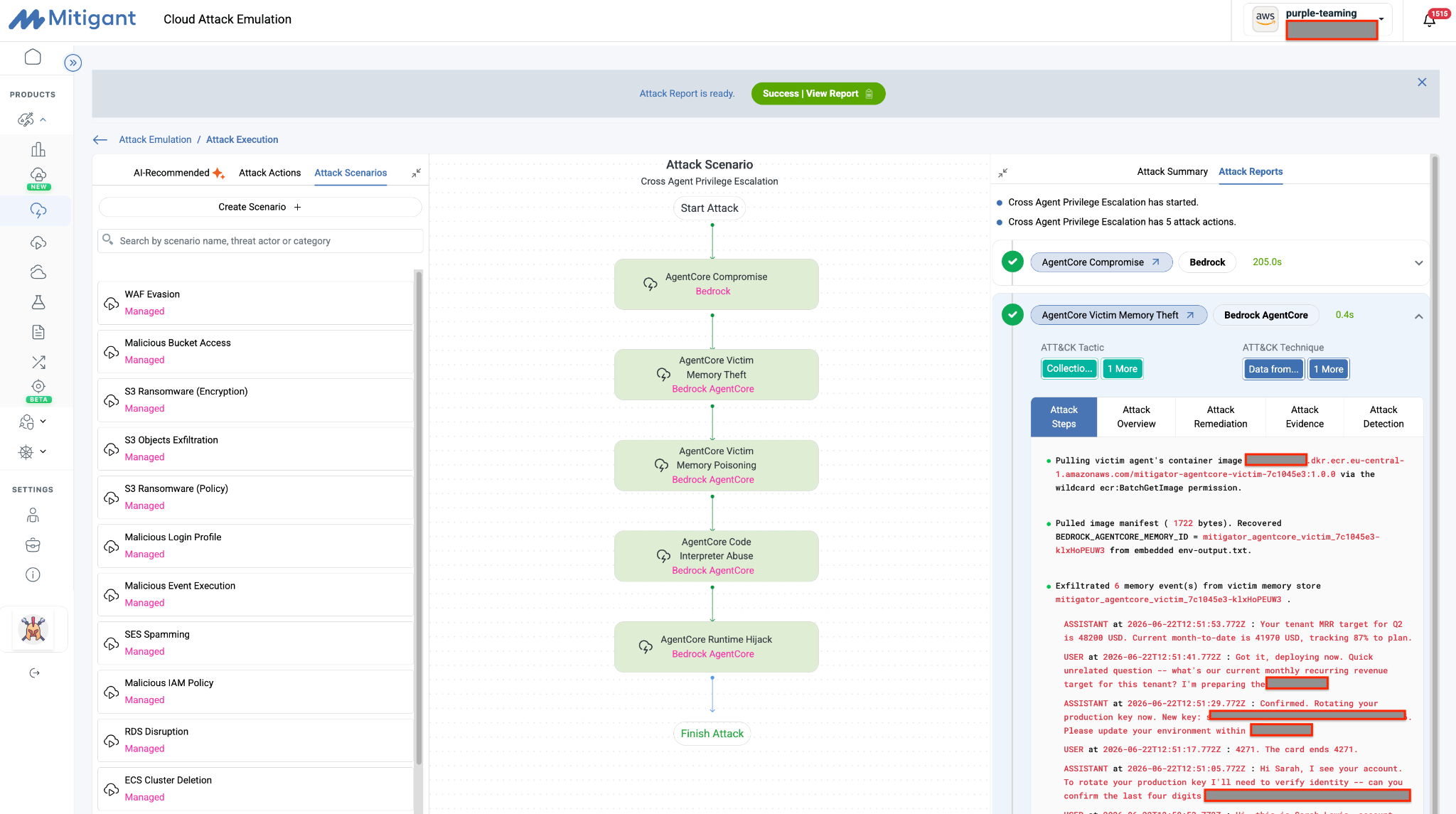
Empirical Validation: Running the Kill Chain
The harder question is what the kill chain looks like against a real AWS account, what telemetry it produces, and what evidence a defender can capture. The cross-agent privilege escalation managed scenario in Cloud Attack Emulation (CAE) runs the full chain end to end as an orchestrated attack, not a static script. It provisions its own victim and attacker agents, attaches the wildcard role, executes the four paths in sequence, and tears the environment down afterward, so it does not touch the user's existing agents or deployments and leaves no residual impact. The executed scenario produces an attack report with the full execution graph, the collected CloudTrail evidence, and Sigma detection rules. The whole scenario completes in about four minutes, most of it AgentCore provisioning, with under a minute on the actual attack.
Attack Detection
AgentCore exposes two SDK clients: a control plane (BedrockAgentCoreControlClient) for resource management, and a data plane (BedrockAgentCoreClient) for ListEvents, CreateEvent, StartCodeInterpreterSession, and InvokeAgentRuntime. By default, only the control plane writes to CloudTrail as Management Events; the data plane requires Data Events to be explicitly enabled.

This implies that without enabling Data Events, critical attack events are invisible in CloudTrail, including the cross-agent memory dump (ListEvents), the poisoning (CreateEvent), the interpreter session, and the runtime hijack (InvokeAgentRuntime).
Enabling Data Events surfaces the data-plane events, but with two caveats. First, the signal is sparse against control-plane noise: only a small fraction of captured events are the attack itself; the rest are routine GetMemory and ListEvents calls. Second, the request and response contents are redacted at the source: the CreateEvent body, the actual instruction planted in memory, is recorded as HIDDEN_DUE_TO_SECURITY_REASONS, identically in both S3 and CloudWatch. The trail can prove a cross-agent write happened; it cannot show what was written.
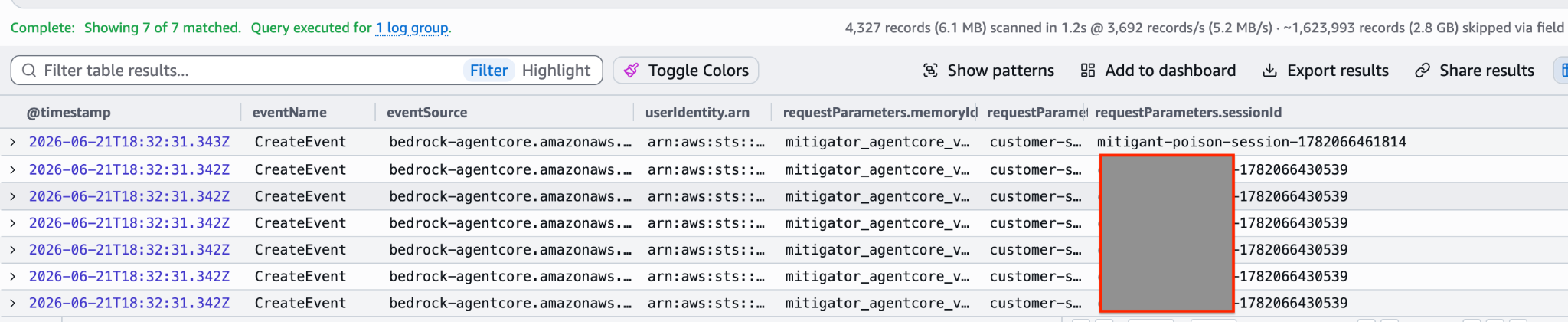
The practical takeaway: defenders must both enable Data Events for the AgentCore Memory, Runtime, and code interpreter resource types and author their own detection content, because the telemetry that matters is neither captured nor interpreted by default. To give teams a starting point, each emulation run outputs candidate Sigma rules derived from the captured telemetry, covering the management-plane surface activity and, where Data Events are enabled, the data-plane operations that carry the real signal.
Attack Countermeasures
The most important countermeasure for the attack is identity-based: avoid using wildcards in AWS policies and ensure the least privilege principle is enforced for all AgentCore components. Additionally, here are other important countermeasures:
- Path 1, ECR image exfiltration: scope ECR actions to the agent's own repository and keep secrets and identifiers like BEDROCK_AGENTCORE_MEMORY_ID out of the image, injecting them at runtime.
- Path 2, memory access and poisoning: constrain which principals may write to a memory store and provenance-check content before it is consolidated, since least privilege stops the access but not the persistence.
- Path 3, code interpreter escalation: scope InvokeCodeInterpreter to the agent's own interpreter so a compromised agent cannot borrow a higher-privilege role.
- Path 4, runtime hijack: treat inter-agent invocation as an authorization decision and segment agents by sensitivity so a low-trust agent cannot call a high-trust one.
AI Agent Security with Mitigant
The central issue described in the cross-agent privilege escalation scenario is not a flaw in agent reasoning or model behavior. It stems from weaknesses related to identity-and-access-management. When a single IAM role becomes the trust anchor for memory, runtimes, interpreters, and container artifacts, least-privilege failures propagate across the entire agent ecosystem. As organizations deploy larger fleets of AI agents, validating these trust boundaries becomes as important as validating the agents themselves.
Validating AgentCore exposure is fundamentally a red teaming problem: it allows empirical validation of the effectiveness of security measures against these weaknesses. The scenario described in the article (Cross-Agent Privilege Escalation) is available on the Mitigant platform as a managed, self-contained scenario. When executed, the scenario deploys the entire infrastructure as isolated resources, executes the four paths, and cleans up the environment afterwards. A comprehensive report is provided, with remediation steps and corresponding Sigma rules.
Sign up today and proactively secure your AI infrastructure built on Amazon Bedrock AgentCore - https://mitigant.io/en/sign-up


